
Deep dive into OpenAI completion parameters
In this post I will describe in detail, how to use different parameters in the OpenAI completion API. We will discuss both the theoretical understanding as well as some code snippets for references.

Disclaimers
This disclaimer pertains to the code and output presented in this post. It's worth noting that the GPT-3 models used are large and inherently random, so the exact results shown here may not be reproducible. However, the output shown is authentic and the explanations provided for each parameter are logically sound.

Contents
In this ongoing conversational AI war, large language models have already put their founding stones. And ChatGPT continues to maintain the buzz all around the globe. Although everyone can use such conversational AI very easily, but creating business values is not as trivial as it sounds. Typically, there are two categories that are most important when using such large language models.
Prompt engineering, prompt optimization, and prompt management.
Parameters and/or arguments of the API.
In this post, I will cover the second part (in-depth analysis of API parameters). Although, I will write multiple posts on prompt engineering, prompt optimization, and prompt management in the future as well.
First Thing First
Before diving deep into the discussion of the parameters, it would be good to understand in simple words, how generative language models work. As I will keep pulling this reference throughout the post.
A generative language model is a type of machine learning algorithm that generates text based on the patterns it learned from the training data. It works by creating a model that can mimic the statistical properties of the language, such as word usage and sentence structure, and then using that model to generate new text that is similar to the original data. The model generates new text by starting with a prompt, such as a sentence or a word, and then predicting the next word in the sequence based on the patterns it learned from the training data.
So, in a nutshell, a generative language model predicts the next word(s). But, how does it predict?
Is it a straight random prediction?
Well not really. In simple terms, it predicts based on the probability distribution of the words.
Let’s understand it in more detail. When a generative language model is trained, it uses a lot of text data for training, and the text data is broken down into tokens. There is quite a difference between a token and a word, but to keep it simple we can consider tokens as words. So, the text data is broken down into words. Now, when a user provides a prompt to the model, it searches for the next word which has the highest probability and returns it.
Let’s assume our model was trained using only 10 words (tokens) and given an input prompt the model checks for the probability distribution of all the 10 words (tokens) similar to the below probability plot and returns token_9 as token_9 (orange plot) has the maximum probability among the other tokens. It is the easiest way of understanding the working principle of the generative language models. There are more complexities involved in it and we will discuss some of them with respect to each of the parameters.
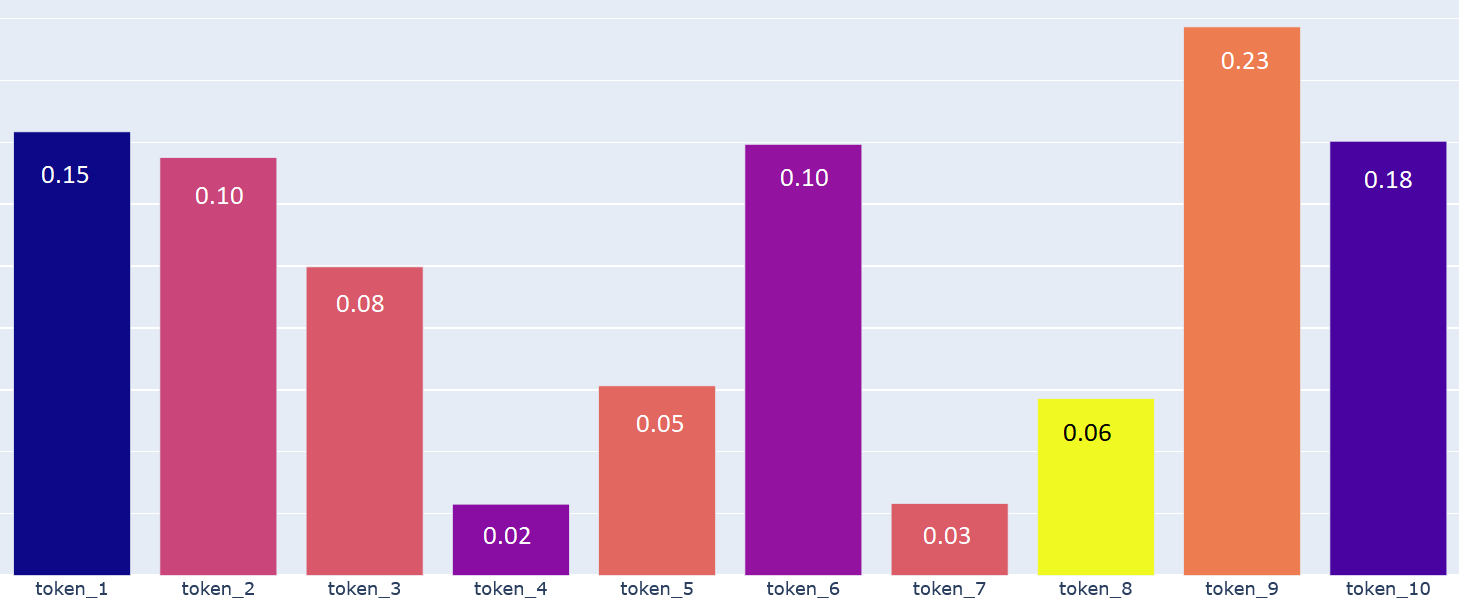
Please keep an eye on the above probability distribution chart as I will refer to it in the later sections as well.
Parameters to OpenAI completion API
ChatGPT is not yet released for programmatic use or API-based use (ChatGPT Plus is released in the US and for other countries, you have to be on the waitlist by filling out a form). So I will use OpenAI API GPT-3 based models.
OpenAI completion API is one of the widely used applications and is quite similar to the ChatGPT interface. You can use their playground to do some experiments.
All the necessary parameters are beautifully explained on the OpenAI documentation page itself. Here I will try to demystify them more.
model
The ID of the model you want to use. OpenAI has mainly three categories of models. GPT-3, Codex, and Content filter. We will use the GPT-3 model and under GPT-3 there are quite a few models available. text-davinci-003 is the latest one under GPT-3 and this will be the model ID we are referring to, in this parameter discussion.
prompt
This parameter is one of the important ones. It is the set of input and/or instructions which will be responsible for the final output. Remember the prompt engineering and optimization that we talked about in the beginning? Here it is needed the most. Although for easy use I will use simple prompts or instructions for our upcoming examples.
max_tokens
A generative language model generates streams of text. Now a valid question would be how long would be the response of the model. Well, it depends on many things like the prompt that you have provided. But also by using this parameter you can restrict the output length.
import openai
openai.api_key = "Your_API_Token"
response = openai.Completion.create(
model="text-davinci-003", # Model ID
prompt="Please write a summary about balck hole.", # The prompt
max_tokens=256, # The maximum number of tokens to generate in the completion
)
print(response["choices"][0]["text"])
'''
Output:
A black hole is an astronomical object with an incredibly strong gravitational pull. It is formed when an incredibly large and dense mass, such as ...
'''If you want to get your API token a.k.a secret key please visit this page.
I have truncated the actual output, but it is quite long because max_tokens was set to 256. Let’s see what happens if we reduce the token length.
import openai
openai.api_key = "Your_API_Token"
response = openai.Completion.create(
model="text-davinci-003",
prompt="Please write a summary about balck hole.",
max_tokens=30, # Reduced it from 256 to 30
)
print(response["choices"][0]["text"])
'''
Output:
A black hole is an object in space characterized by an incredibly strong gravitational pull that is so strong that not even light can escape its reach.
'''Here I have not truncated the output. In short, it is quite easy to understand the concept of max_tokens.
One important point is that every model has a limit of context length (length of prompt + max_tokens). In our case text-davinci-003 has a limit of 4096 tokens. If we calculate, in our first example the context length was 267 because the prompt had 7 words and max_tokens was 256, but in the second example context length became 37 in a similar way.
To save on cost, it is crucial to have an understanding of how to utilize the max_tokens parameter, as more tokens equate to a higher expense.
The max_tokens parameter also plays an important role in regard to rate limits, but I won't go into further detail. For more information, you can refer to this source.
All the above calculation I have done to get the context length is taking the assumption that I already made for simplicity, which is tokens and words are the same.
temperature
One crucial aspect to consider is this parameter, as it regulates the randomness of the model's response. It can take values between 0 and 2, with higher numbers leading to more unpredictable responses, rendering the model's output stochastic. Conversely, lower values result in a more predictable, deterministic response from the model.
In a nutshell, if the temperature value is near 0 and if we run the same prompt multiple times, we will see almost the exact response every time. Similarly, if the temperature value is very high and if we run the same prompt multiple times, we will see different responses almost every time.
import openai
openai.api_key = "Your_API_Token"
response = openai.Completion.create(
model="text-davinci-003",
prompt="How are you?",
temperature=0, # Temp is very low
)
print(response["choices"][0]["text"])
'''
Output after running it for 3 times
I'm doing well, thank you. How about you?
I'm doing well, thank you. How about you?
I'm doing well, thank you. How about you?
'''import openai
openai.api_key = "Your_API_Token"
response = openai.Completion.create(
model="text-davinci-003",
prompt="How are you?",
temperature=1.5, # Temp is very high
)
print(response["choices"][0]["text"])
'''
Output after running it for 3 times
I'm doing ok, thanks for asking. How are you?
I'm doing well, thank you. How are you?
I'm doing well, thanks for asking. How about you?
'''From the above examples, it is quite clear how different values the temperature making the model’s response either deterministic or stochastic.
But, more importantly, how does this work internally?
To understand this, refer to the Sample Probability Distribution plot discussed earlier. The generative language model predicts the next word by picking the word (token) having the highest probability. It exactly happens when temperature is 0 or a very low value. In our case, token_9 will be picked every time if temperature is 0 or a very low value. That is the reason we have seen exactly the same output in the first example where I set temperature=0.
On the other hand, if temperature is set to a very high value, the model will not directly pick the word (token) having the highest probability, rather it will collect multiple tokens (token_1, token_6, token_9, token_10 four our case) having the higher side of probability distribution and then sample one of the tokens randomly. That is the reason we have seen different outputs in the second example where I set temperature=1.5.
You might have noticed, I have highlighted the phrase ‘sample one of the tokens randomly‘ because the parameter is also known as sampling temperature mentioned in OpenAI documentation.
top_p
This parameter works exactly the same way temperature does. It takes a value between 0 and 1. Higher the value more the stochastic response, lower the value more the deterministic response.
import openai
openai.api_key = "Your_API_Token"
response = openai.Completion.create(
model="text-davinci-003",
prompt="How are you?",
top_p=0,
)
print(response["choices"][0]["text"])
'''
Output after running it for 3 times
I'm doing well, thank you. How about you?
I'm doing well, thank you. How about you?
I'm doing well, thank you. How about you?
'''import openai
openai.api_key = "Your_API_Token"
response = openai.Completion.create(
model="text-davinci-003",
prompt="How are you?",
top_p=0.9,
)
print(response["choices"][0]["text"])
'''
Output after running it for 3 times
I'm doing ok, thank you. How are you?
I'm doing well, thank you. How about you?
I'm doing well, thanks for asking.
'''Examples are similar as well. But, interestingly the internal working of top_p parameter is different than temperature. It is also called the nucleus sampling method.
To understand, again we will look at the Sample Probability Distribution plot. If you notice each bar (token) is associated with a decimal number and the summation of all the numbers for all the tokens is 1. It is a probability distribution so the summation will always be 1.
Let's consider two scenarios. When top_p is set to 0.2, meaning that only the words (tokens) comprising the top 20% probability mass are considered. The idea of the probability mass is not being discussed here, but to put it simply, the language model will only take into account the 20 most probable words or tokens that could come next. On the other hand, when top_p is set to 0.9, the model will consider the 90 most probable words or tokens. So, the number of words (20 words or 90 words) is varying based on the parameter value which essentially varies the output we will get, making it either stochastic (when the number of words is more) or deterministic (when the number of words is less).
OpenAI generally recommend altering
top_portemperaturebut not both.
logprobs
logprobs parameter is the best parameter to visualize all the probability distribution concepts I was referring to before. This parameter allows you to inspect the probabilities on the most likely tokens, as well as the chosen tokens. You can extract the values and plot them in the same way that we were discussing above. Let’s see an example.
import openai
openai.api_key = "Your_API_Token"
response = openai.Completion.create(
model="text-davinci-003",
prompt="How are you doing?",
logprobs=3
)
print(response["choices"][0]["text"])
print(response["choices"][0]["logprobs"]["top_logprobs"])
'''
Output of the first print statement (the actual response)
I'm doing well, thanks. How about you?
Output of the second print statement (the log probabilities)
{
"I": -0.0016188136,
"Pretty": -6.6341195,
"Thanks": -9.836748
},
{
" am": -5.1309304,
"'m": -0.0060013067,
" are": -9.609768
},
{
" doing": -0.00040832703,
" good": -8.421555,
" great": -9.251456
}
.
.
.
'''As you can see from the above example, how the tokens were selected based on their probability distribution. I have highlighted the tokens so that you can map them with the actual response. You can also extract them and plot them as a probability distribution for better visualization.
presence_penalty
The presence_penalty is the parameter that allows the API to penalize suggestions that are too close to the input text. The goal of this parameter is to encourage the API to generate more diverse and original completions.
The presence penalty is applied internally by adjusting the score that the API assigns to each suggestion based on how close it is to the input text. For example, if the input text is "The sun rises in the east" and the API generates a response that repeats the tokens multiple times, the presence penalty would lower the score of this suggestion, making it less likely to be selected as the final completion.
In simple terms, the presence penalty helps to prevent the API from simply repeating what it has already been given and encourages it to generate more creative and interesting completions.
import openai
openai.api_key = Your_API_Token
response = openai.Completion.create(
model="text-davinci-003",
prompt="The sun rises in the east ",
presence_penalty=-2, # It can take value between -2 and 2
max_tokens=50
)
print(response["choices"][0]["text"])
'''
Output:
The sun rises in the east and everyday it rises in the east. In the Northern Hemisphere The sun rises in the east and sets in the west
'''import openai
openai.api_key = Your_API_Token
response = openai.Completion.create(
model="text-davinci-003",
prompt="The sun rises in the east ",
presence_penalty=2, # It can take value between -2 and 2
max_tokens=50
)
print(response["choices"][0]["text"])
'''
Output:
The sun rises in the east each day. As it moves across the sky, it appears to travel from east to west, or left to right (during Northern Hemisphere days). The direction of sunrise is determined by the Earth's rotation on ...
'''The output clearly demonstrates how presence_penalty functions and how can be useful for various purposes. If you require unique ideas, a high presence_penalty value is recommended. On the other hand, if you need to correct grammar errors, a low presence_penalty is better, as it will ensure that the same tokens are repeated while fixing the mistakes.
A detailed mathematical explanation is provided here.
frequency_penalty
The frequency_penalty parameter is a mechanism for controlling the balance between exploring new and creative completions versus sticking to more common and familiar ones. As we discussed earlier the API generates completions by sampling from a language model that has been trained on a large corpus of text. These models have been trained to predict the likelihood of a word or sequence of words, given the preceding context. The frequency_penalty parameter can be used to reduce the likelihood of sampling words or sequences of words that the model thinks are more likely. This in turn makes it more likely that the API will generate novel and unexpected completions, rather than repeating common patterns or themes.
Internally, the frequency_penalty is applied by raising the log probability of each word or sequence of words to the power of the frequency_penalty value. This has the effect of reducing the relative probability of more frequent words or sequences of words, making it more likely that the API will sample from less likely options. The actual implementation details of how this works can be quite complex and you can get some idea here. However, by adjusting the value of the frequency_penalty, you can effectively control the level of exploration vs exploitation in the generated completions.
import openai
openai.api_key = Your_API_Token
response = openai.Completion.create(
model="text-davinci-003",
prompt="How does gravity work?",
frequency_penalty=-2, # It can take value between -2 and 2
max_tokens=50
)
print(response["choices"][0]["text"])
'''
Output:
Gravity is a natural phenomenon by which all objects with mass are brought toward one another. It is one of the fundamental forces of the universe. Gravity is the one of the the the the the the the the the the the the the the
'''So boring and repeating patterned responses (Yes, it literally printed ‘the’ that many times).
import openai
openai.api_key = Your_API_Token
response = openai.Completion.create(
model="text-davinci-003",
prompt="How does gravity work?",
frequency_penalty=-2, # It can take value between -2 and 2
max_tokens=50
)
print(response["choices"][0]["text"])
'''
Output:
Gravity is an attractive force between any two objects that have mass. The strength of gravity depends on the amount of mass present, and how far apart the objects are from each other. Gravity works by pulling together all matter in the universe ...
'''Then how is it different from presence_penalty?
The presence_penalty and frequency_penalty parameters serve similar purposes, but they operate at different levels of abstraction and apply different forms of penalties.
The frequency_penalty is a mechanism for controlling the balance between common and uncommon completions by penalizing more frequent words or sequences of words. It reduces the relative probability of more frequent options and makes it more likely that the API will generate less common completions.
On the other hand, the presence_penalty is a mechanism for controlling the balance between completions that are present in the input prompt and completions that are not present. It reduces the relative probability of options that appear in the prompt, making it less likely that the API will generate redundant completions. The presence_penalty can be useful for avoiding repetitions, whereas the frequency_penalty can be useful for encouraging novelty and diversity.
In summary, the frequency_penalty and presence_penalty parameters can be used together to control the balance between exploration and exploitation, novelty and familiarity, and repetition and diversity in the generated completions.
Conclusion
While a number of parameters exist within the OpenAI completion API, I have only covered the most critical and essential parameters in this explanation. These parameters, when experimented with, can significantly impact the output of the API, leading to desirable results. However, there are other parameters that are straightforward and self-explanatory, and you may find additional information regarding these parameters in the official OpenAI documentation. The purpose of this discussion was to provide an understanding of the parameters that play a crucial role in obtaining successful results from the API.
Thank you for reading this article. Consider subscribing to this post if you found its contents valuable and enlightening. Your support will be a source of inspiration for crafting future posts that are equally informative and engaging.